Cloud based server solutions are now the default platform for modern software. The promise is simple, build faster, scale on demand, and save money you can prove to a CFO. In practice, you only get all three when architecture, automation, security and FinOps work as a single system. This guide distils a pragmatic approach we use with engineering teams to design cloud server platforms that are resilient, cost aware and ready for growth in 2025.
What counts as a cloud based server solution
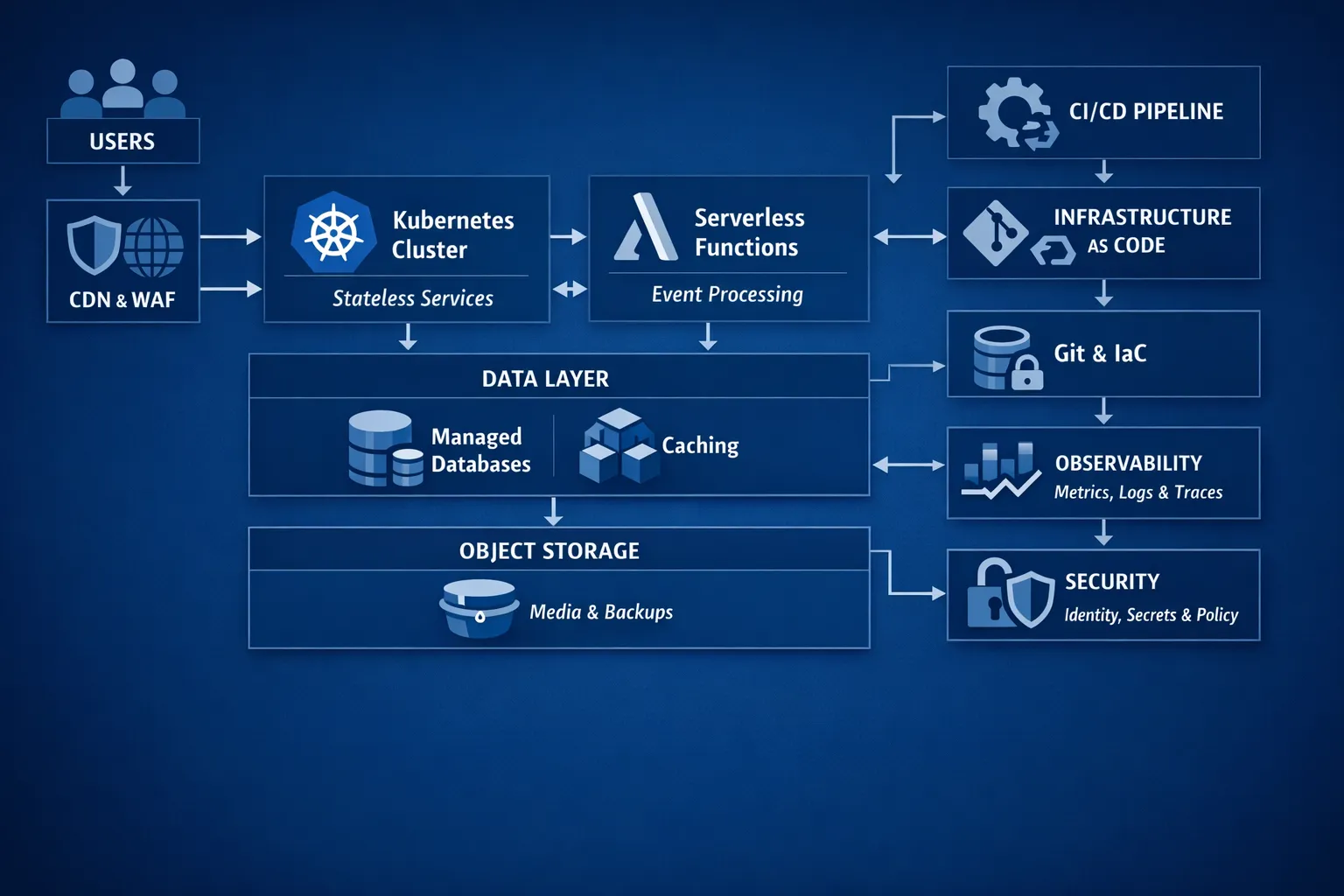
Cloud based servers are no longer just virtual machines. The most effective platforms blend several layers so each workload runs in the best place for speed and cost:
- IaaS virtual machines for lift and shift, commercial off the shelf software and stateful services
- Containers on a managed Kubernetes service for microservices and high release velocity
- Serverless functions and managed APIs for bursty, event driven tasks at very low operational overhead
- Managed data services for relational, key value, document and analytics use cases
- A delivery system, CI/CD plus Infrastructure as Code, that makes every change fast, reversible and auditable
- Observability and security that give evidence of reliability, compliance and cost control
You do not need every component on day one. The goal is a platform you can evolve safely, with the right guardrails from the start.
Build, the foundation that unlocks speed
The build phase is where most of your long term cost and reliability is decided. A few non negotiables make a huge difference.
Start with a secure landing zone and identity
- Separate environments by account or subscription, production is isolated from non production
- Enforce single sign on, MFA and least privilege IAM roles
- Centralise logging, backups and key management so audit evidence is always available
Choose the right compute model for each workload
| Option | How it works | Best for | Strengths | Watch outs |
|---|---|---|---|---|
| Virtual machines | Long lived instances you manage | Legacy apps, commercial software, stateful services | Familiar, broad compatibility | More manual operations, VM sprawl and idle cost |
| Containers on Kubernetes | Packaged services scheduled onto a cluster | Microservices, APIs, batch jobs | Portability, high density, policy and automation | Operational overhead if unmanaged, plan for cluster autoscaling |
| Serverless functions | Code executes per event, scales to zero | Event processing, automation, low traffic endpoints | Minimal ops, pay only when used | Cold starts, execution limits, vendor specific features |
A simple pattern is to keep state and heavy commercial software on VMs or managed services, move stateless services to containers, and push spiky or glue logic to serverless.
Think data and integration early
- Use managed relational databases for transactional systems, pair with read replicas and caching
- Use managed key value or document stores for session, profile and content metadata
- Decouple with queues and streams so spikes do not overload databases
- Put a Content Delivery Network in front of static assets to reduce latency and egress
Automate delivery and operations from day one
- Infrastructure as Code to create everything repeatably
- CI/CD with automated tests, quality gates and progressive delivery
- Observability built in, metrics, logs and traces with service level objectives
Connect your growth stack
Cloud platforms often need to feed marketing and sales systems. Event driven integrations make that easy without loading your core apps. For example, you can route community signals into your pipeline using tools that can turn Reddit conversations into customers, then trigger serverless enrichments before creating leads in your CRM. Keep this work at the edge of your platform so it can scale independently.
Scale, from first users to peak demand
Scaling is not a feature to bolt on later. Design each tier to grow and recover predictably under load.
Scale stateless services automatically
- Horizontal Pod Autoscaler on Kubernetes, target CPU or latency, and Pod Disruption Budgets to protect availability
- Cluster Autoscaler to add or remove nodes based on pending pods
- Ingress with path and host routing so one load balancer can fan in to many services
If your traffic is event driven, use event metrics rather than CPU to drive scale. We implemented event driven auto scaling with KEDA for a UK healthcare provider so queue length and custom metrics added capacity exactly when needed.
Manage state at scale without drama
- Prefer managed database services with multi AZ high availability
- Add read replicas behind a router for heavy reads, pair with Redis for hot keys
- Use write queues for burst smoothing when spikes would overwhelm the primary
- Partition or shard only when you can monitor and operate it, start simple first
Build resilient networks
- Use a CDN and Web Application Firewall to take the edge load and stop obvious attacks
- Separate public and private subnets, restrict egress, and peer or transit gateway for hybrid
- Health checks and failure domains so you can survive zone failures without paging all night
Prove scale with tests, not hope
Run load tests that mimic peak user journeys. Treat performance regressions like failing tests, because they are. Instrument p95 and p99 latencies and track your error budget burn so you can decide when to ship and when to harden.
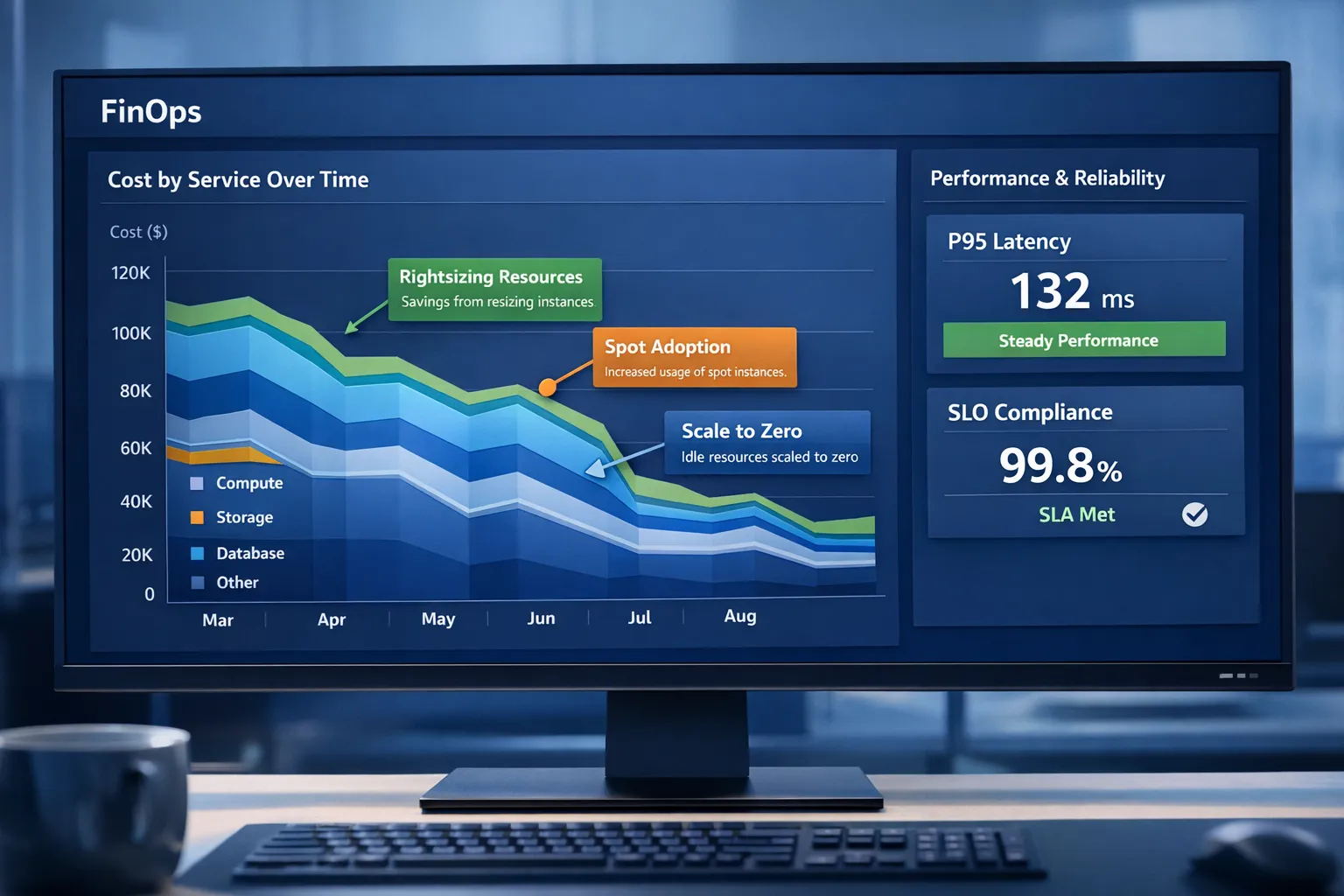
Save, without slowing delivery
Most cloud waste is predictable. Tackle visibility first, then apply a mix of quick wins and structural changes.
Quick wins that pay back in weeks
- Rightsize long lived instances and containers, set sensible CPU and memory requests
- Turn off non production out of hours with schedules
- Move block storage to the right class and clean up snapshots and unattached volumes
- Consolidate load balancers with an Ingress or API gateway pattern
We helped a travel company achieve a 30 percent EKS cost reduction using a balanced mix of spot, right sizing and safe disruption budgets.
Structural savings that compound
- Shift to managed services and serverless where workloads are intermittent, scale to zero saves real money
- Use spot or preemptible compute for stateless and batch, design for interruption and fast rescheduling
- Adopt Graviton or equivalent modern CPU families where compatible for better price performance
- Optimise telemetry, keep high value metrics and traces, tier logs to lower cost storage
- Place data close to consumers and cache at the edge to cut egress
Savings levers at a glance
| Lever | Where it applies | Typical impact | Key enabler |
|---|---|---|---|
| Rightsizing and scheduling | VMs and containers | Immediate reduction in idle spend | Observability and automation |
| Spot and interruption tolerant design | Batch, stateless workers | Significant unit cost drop | Pod disruption budgets and queues |
| Scale to zero | Event driven services | You only pay when events arrive | KEDA or serverless functions |
| Storage class and retention | Block, object, logs | Lower ongoing storage bill | Tiering policies and lifecycle rules |
| Data transfer reduction | CDN, caches, locality | Lower egress and latency | Caching and regional placement |
Savings are not the whole story. The best programmes raise delivery speed while cost trends go down. That is how you preserve engineering morale and avoid the boom and bust of one off cost cuts.
Security and compliance by design
Security cannot be a separate workstream. Bake it in so auditors and customers gain confidence while developers keep shipping.
- Identity first, centralised SSO, MFA and short lived credentials
- Encrypt data at rest and in transit, manage keys in a dedicated service
- Secrets stay out of code and images, use a vault or the cloud secret manager
- Signed artefacts and image scanning in the pipeline, dependency checks before deploy
- Continuous monitoring and immutable audit logs, ready for evidence requests
A pragmatic 90 day path to production
- Weeks 1 to 3, Baseline and design. Assess your current workloads, choose target compute models, draft a minimal landing zone with identity, network and logging. Define service level objectives and cost guardrails.
- Weeks 4 to 6, Build the foundations. Stand up the landing zone with Infrastructure as Code, create the CI/CD pipeline, deploy observability, and enable basic security controls. Containerise one or two services, keep state on a managed database.
- Weeks 7 to 9, Prove scale and resilience. Add autoscaling, introduce queues for burst control, put a CDN and WAF in front, and run realistic load tests. Tune resource requests and set initial budgets and alerts.
- Weeks 10 to 12, Operate and optimise. Turn on schedules in non production, adopt spot where safe, reduce telemetry noise, and publish a simple monthly cost and reliability report. Plan the next wave of services to modernise.
This cadence keeps risk low and value visible, which helps executives and engineers stay aligned.
Proof points from the field
Outcomes matter more than patterns. A few highlights from recent work show what is realistic when the approach is joined up.
- Event driven scale, A UK healthcare provider introduced dynamic scaling on Kubernetes using KEDA so services rose to meet emergencies then fell back during quiet periods. Manual scaling dropped and availability improved. Read the story, event driven auto scaling with KEDA.
- Cost control with speed, A hospitality company cut their EKS bill by 30 percent and eliminated service disruptions by pairing spot compute with safe disruption budgets, cluster over provisioning and alerting. See the results, 30 percent EKS cost reduction.
- Smart migration, A mid market SaaS firm turned a struggling DIY Kubernetes migration into a consultant led programme that reduced downtime risk and total cost while delivering 95 percent faster deployments. Learn more, how a SaaS company saved $253K on Kubernetes migration.
How Tasrie IT Services can help
Tasrie IT Services specialises in DevOps, cloud native and automation. We design and implement cloud based server solutions that deliver measurable outcomes, faster shipping, higher reliability and lower total cost. Our team brings senior engineering expertise across Kubernetes, CI/CD, Infrastructure as Code, cloud landing zones, observability, security and managed services. We also help with data analytics and business process automation so the platform supports every part of the business.
If you want to build the right foundations, scale confidently and save without slowing down, start a conversation with our team. We will meet you where you are, and get you to where you need to be with a plan you can execute and measure.
Bottom line, with the right architecture and operating model, cloud based server solutions let you build fast, scale safely and save money you can prove. The best time to start is when your next project needs a home. The second best time is today.