If your board is asking for faster delivery, lower run costs and stronger risk controls in 2025, Infrastructure as a Service is likely the foundation you will modernise on. This guide explains IaaS in pragmatic terms for CTOs, how it differs from PaaS and SaaS, when to choose it, and the operating model shifts that actually unlock its value.
What Infrastructure as a Service really is
Infrastructure as a Service, often shortened to IaaS, provides virtualised compute, storage and networking that you consume on demand. You get building blocks, not platforms. You design the topology, manage operating systems, patching schedules, encryption, IAM, backup policies and deployment automation, while the provider runs data centres, physical hardware and the virtualisation layer.
For formal definitions of cloud service models and essential characteristics such as elasticity and measured service, see the NIST definition of cloud computing in Special Publication 800-145 (NIST SP 800-145).

IaaS vs PaaS vs SaaS at a glance
| Stack layer | IaaS responsibility | PaaS responsibility | SaaS responsibility |
|---|---|---|---|
| Facilities, physical security, power | Provider | Provider | Provider |
| Servers, storage, network hardware | Provider | Provider | Provider |
| Hypervisor, virtualisation | Provider | Provider | Provider |
| Operating system and patching | Customer | Provider | Provider |
| Middleware and runtime | Customer | Provider | Provider |
| Application code and config | Customer | Customer | Provider |
| Data, identities, access policies | Customer | Customer | Shared |
IaaS gives you maximal control and portability, PaaS accelerates delivery but narrows control surfaces, and SaaS outsources the stack entirely. Most enterprises operate a mix across portfolios.
Core IaaS building blocks a CTO should standardise
- Compute, instance families and workload placement: VM families for general purpose, memory or compute optimisation, plus GPU options for AI and HPC. Standardise images and hardening baselines.
- Storage tiers: block for low latency, object for durability and scale, file for lift and shift. Apply lifecycle policies and encryption keys as code.
- Networking and connectivity: VPC or VNet design, subnets, routing, private link, load balancing, DNS, site-to-site VPN and direct interconnect for hybrid.
- Identity and access: Single sign on integration, role based access, short lived credentials, break glass patterns and least privilege.
- Security controls: Key management, secrets management, WAF, DDoS protection, EDR on hosts, baseline CIS benchmarks, vulnerability scanning and drift detection.
- Observability: Centralised logging, metrics, distributed tracing and alerting with SLOs for platform components.
- Backup and resilience: Policy based backups, cross region replication, tested recovery runbooks and business impact aligned RTO and RPO.
- Automation: Infrastructure as Code with Terraform or similar, immutable images, golden AMIs, configuration as code and GitOps for repeatability.
These are the minimum primitives to productise in a landing zone so application teams have paved roads rather than starting from scratch on each project. For a deeper look at foundational cloud patterns, see our guide on Cloud Native Fundamentals.
Strategic advantages, and the trade offs
Advantages you can bank on when IaaS is implemented well:
- Speed and agility: Provision in minutes, scale elastically, iterate architectures without hardware lead times.
- Financial flexibility: Shift from capital expenditure to operating expenditure, align spend with demand, adopt unit economics at the product level.
- Control and portability: Retain control of OS, network and security architecture, build to open standards and multi cloud abstractions if required.
- Ecosystem leverage: Pair IaaS with managed databases, analytics, AI accelerators and message buses when those fit, without losing core control.
Trade offs to plan for:
- Operational responsibility: You own OS patching, hardening, incident response and compliance. The shared responsibility model is real.
- Complexity and skills: Networking, identity, encryption at scale and cost controls require platform engineering discipline.
- Hidden costs: Data transfer, idle resources, snapshot sprawl and observability pipelines can quietly grow your bill if not governed.
A decision framework for CTOs evaluating IaaS
Consider these lenses when setting your service model strategy for a portfolio or a new platform.
- Workload characteristics: Stateful versus stateless, latency sensitivity, data gravity, licensing constraints, GPU requirements and compliance scope.
- Control surfaces: Do you need custom kernels, non standard runtimes, strict network isolation or bespoke security agents? That points to IaaS.
- Time to value: If a platform service can meet 80 percent of needs safely, PaaS or SaaS may be faster for that workload. Choose deliberately, not by habit.
- Operating model readiness: Do you have platform and SRE teams to own patching, SLOs, incident response and change management? If not, phase adoption with capability building.
- Vendor strategy: Single cloud for focus and economies of scale, or targeted multi cloud for regulatory, latency or negotiation leverage. Keep multi cloud purposeful.
- Region and regulatory requirements: Data residency, encryption controls, logging retention and local entity requirements vary by jurisdiction. IaaS can meet strict requirements, but governance must be encoded from day one.
If your organisation is expanding into the Middle East, align cloud region choices with local entity and compliance steps. For example, Australian firms setting up in the UAE often pair IaaS region deployment with specialist business setup assistance in Dubai to streamline licensing and legal documentation while technology teams focus on landing zones and security controls.
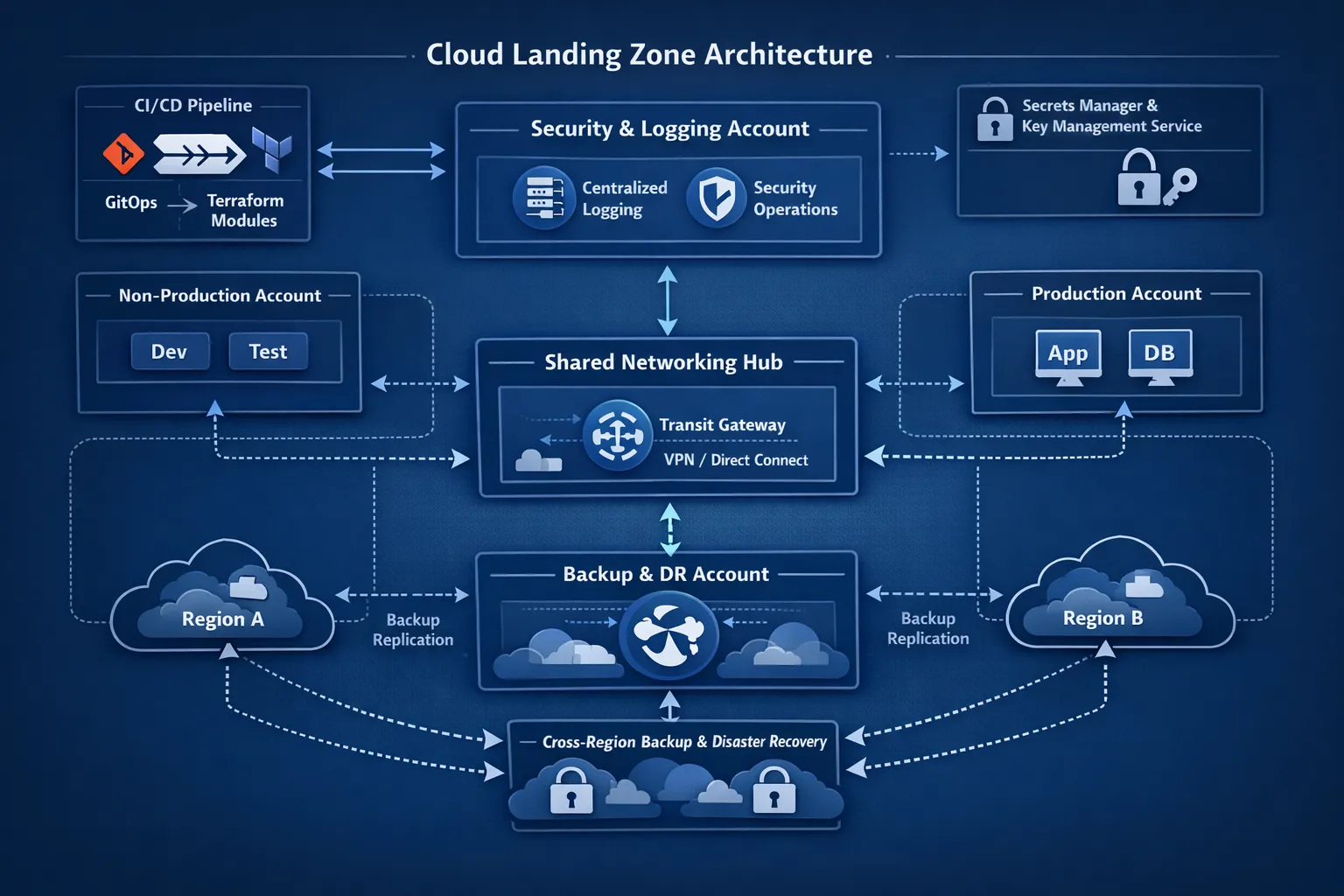
A modern IaaS blueprint that scales
The high level architecture below is provider agnostic, with obvious equivalents on AWS, Azure and Google Cloud. The key is to treat it as a product that you iterate, not a one time project.
| Capability | What good looks like | Outcome |
|---|---|---|
| Landing zone | Multi account or multi subscription structure, guardrails, baseline networking, centralised logging, identity integration | Safe defaults, separation of duties and blast radius control |
| Infrastructure as Code | Terraform modules, versioned in Git, code reviews, policy checks in CI, GitOps deployment | Repeatability, auditability and fast change with low risk |
| Golden images | Hardened images, CIS baselines, pre installed agents, image pipeline | Consistent security posture and faster patch rollouts |
| Network architecture | Hub and spoke, private service endpoints, egress controls, DNS patterns | Predictable connectivity and data exfiltration controls |
| Secrets and keys | Central KMS and secrets manager, envelope encryption, rotation policies | Reduced secret sprawl and compliance alignment |
| Observability | Logs, metrics, traces, SLOs, runbooks, on call and escalation policy | Reduced MTTR and clear reliability targets |
| Security operations | Vulnerability scan, EDR, WAF, DDoS, threat feeds, automated remediation | Shift left and continuous risk reduction |
| Backup and DR | Tiered backups, cross region replication, quarterly restore tests | Confidence in recovery and audit evidence |
| Cost controls | Tagging standards, budgets, alerts, rightsizing and scheduling policies | Spending predictability and unit cost visibility |
| Kubernetes platform (optional) | Managed control plane, GitOps, policy as code, multi tenancy isolation | Consistent app runtime on top of IaaS |
For implementation details on platform discipline, our playbook on Cloud Engineering Best Practices for High Scale Teams is a useful companion.
Operating IaaS like a product
Owning IaaS is not just provisioning accounts. It is an ongoing commitment to reliability, security and cost efficiency.
- Reliability and SRE: Define service level objectives for the platform itself, measure error budgets, automate rollbacks and keep toil low with standardised modules.
- Change management through Git: All infrastructure changes flow through pull requests, automated tests and policy checks. No click ops in production.
- Patch and image pipeline: Patch monthly at least, rebuild immutable images and roll out safely. Track exposure windows for CVEs.
- Incident response: Run blameless post mortems, tag root causes to backlog, fix it once in code and share learnings across teams.
- Capacity and performance: Autoscale where possible, set sensible instance defaults, remove zombie resources, benchmark critical paths periodically.
The AWS Well Architected Framework is a practical reference across operational excellence, security, reliability, performance efficiency, cost optimisation and sustainability (AWS Well Architected).
Cost management that actually works
Run a simple 90 day FinOps programme to establish control without stalling delivery.
- Measure and tag: Enforce cost allocation tags, ingest cost and usage data, build a shared dashboard by product and environment.
- Quick wins: Schedule dev and test to stop out of hours, rightsize oversized instances, move general purpose volumes to current generation, apply savings plans or committed use for steady state.
- Reduce waste: Delete unattached volumes and idle snapshots, tune log retention, compress and tier object storage with lifecycle rules, review egress patterns.
- Govern: Budgets and alerts per team, pre approved instance families, guardrails that block untagged resources, monthly reviews tied to unit economics.
For a deeper, UK focused approach, our guide to AWS Cloud Cost Optimisation outlines a repeatable Measure, Optimise and Govern framework.
Common risks and anti patterns to avoid
- Lift and shift only, no modernisation: You import old inefficiencies, then pay for them every month. Target clear optimisations post migration.
- Snowflake platforms: Hand built networking or one off images that nobody understands. Treat everything as productised code, not artisan work.
- Default anythings in production: Security groups, passwords, encryption keys and logging settings must follow standards and reviews.
- Unbounded access: Over privileged IAM roles and long lived keys create latent risk. Prefer SSO, short lived credentials and least privilege by default.
- Blind spots in observability: If you cannot answer what changed, who changed it and what the blast radius is, you will struggle to meet SLOs.
Executive level metrics to track
- Reliability: Platform SLO attainment, MTTR, change failure rate and top incident themes.
- Delivery: Lead time for infrastructure changes, deployment frequency for modules and environment provisioning time.
- Cost: Unit cost by product, forecast accuracy and savings plan coverage, cost of idle.
- Security and compliance: Patch currency, vulnerability backlog burn down, policy violations prevented by guardrails.
Where IaaS fits in your portfolio strategy
- Default to IaaS for workloads that need custom OS, advanced networking, strict isolation or specialised hardware such as GPUs.
- Mix in PaaS and managed services when they reduce undifferentiated work without locking you out of required controls.
- Prefer SaaS for non strategic capabilities like email and collaboration where customisation adds little business value.
How Tasrie IT Services helps
Tasrie IT Services specialises in DevOps, cloud native platforms and automation. We help CTOs design and operate IaaS landing zones, implement Infrastructure as Code, stand up Kubernetes platforms, automate CI and CD, integrate observability, uplift security and run AWS managed services with measurable outcomes. If you are planning a migration or need to retrofit governance and cost controls to an existing estate, we can build a pragmatic roadmap, then deliver it with your teams.
Bottom line for CTOs
Infrastructure as a Service is the right abstraction when you need speed without surrendering control. The winners in 2025 are treating IaaS as a product, with strong guardrails, IaC and GitOps, SRE driven operations and clear cost accountability. Start with a minimal but rigorous landing zone, automate everything, and measure relentlessly. The pay off is faster releases, fewer incidents and a cloud bill that reflects real business value rather than waste.